-
[SQLD]공부5일차_1과목마무리!+2과목_241112자격증/SQLD 2024. 11. 12. 13:15반응형
# 최초 등록일 : 2024년 10월 12일 13:35
# 최근 변경일 : 2024년 10월 12일 23:03
# 내용 : 1과목 정리하기 + 1과목 문제풀이공부 4일차는 아래에 링크에~
[SQLD]공부4일차_문제풀면서부족한거채워보기_241109
# 최초 등록일 : 2024년 10월 09일 23:49# 최근 변경일 : 2024년 10월 09일 23:49 # 내용 : 문제풀면서 부족한 부분 체크해보기 슬슬 문제 풀면서 익혀보자부족함은 계속된 이론 정리가 필요해보임 공부 3
doradorabean.tistory.com
------------------------------------------------------------------------------------------------------------------------------
SQLD 문제 풀이------- 데이터 모델과 성능
SQL 자격검정 실전문제
문제: 1~52 / 1~50 --> 계속 반복해야할 거 같다.
다시 풀어봐야하는 항목: 15, 29, 30,38, 40, 43, 46, 48, 52// 5, 22, 29, 30, 34, 35, 40, 41, 43, 46, 49, 50* 제 1차 정규화 > PK에 대해 반복이 되는 그룹(Repeating)이 존재하지 않음
* 정규화 >

------------------------------------------------------------------------------------------------------------------------------
* 정규화 : 중복 데이터를 허용하지 않는 방식으로 테이블을 설계하는 방식
간단하게, 테이블을 분해하는 과정이라고 생각
> 최소한의 데이터만을 하나의 엔터티에 넣는 식으로 데이터를 분해하는 과정
> 데이터의 일관성, 최소한의 데이터 중복, 최대한의 데이터 유연성 위한 과정
> 데이터 이상 현상을 중리기 위한 데이터 베이스 설계 기법
> 엔터티를 상세화하는 과정으로 논리 데이터 모델링 수행 시점에서 고려
> 제 1정규화부터 제 5정규화까지 존재, 실직적으로는 제 3정규화까지만 수행
* 이상현상 : 정규화를 하지 않아 발생하는 현상
> 삽입이상, 갱신이상, 삭제이상
> 특정 인스턴스가 삽일 될 때 정의되지 않아도 될 속성까지도 반드시 입력되어야하는 현상 == 삽입 이상
> 불필요한 값까지 입력해야 되는 현상 == 삽입이상
> 그 외 개신이상, 삭제이상이 발생 할 수 있음
* 정규화단계 > 제 1 정규화(1NF) : 테이블이 컬럼이 원자성을 갖도록 테이블을 분해하는 단계 // 하나의 행과 컬럼의 값이 반드시 한 값만 입력되도록 행을 분리하는 단계
* 정규화단계 > 제 2 정규화(2NF) : 제 1 정규화를 진행한 테이블에 대해 완전 함수 종속을 만들도록 테이블을 분해
> 완전 함수 종속이란, 기본키를 구성하는 모든 컬럼의 값이 다른 컬럼을 결정짓는 상태
> 기본키의 부분 집합이 다른 컬럼과 1:1 대응 관계를 갖지 않는 상태
> PK가 2개 이상일 때 발생하며, PK의 일부와 종속되는 관계가 있다면 분리
* 정규화단계 > 제 3 정규화(3NF) : 제 2 정규화를 진행한 테이블에 대해 이행적 종속을 없애도록 테이블을 분리
> 이행적 종속성이란 a-> b, b->c의 관계에서 a->c가 성립되는 것
> a,b // b,c로 분리하는 것이 제 3정규화
* BCNF 정규화 : 모든 결정자가 후보키가 되도록 테이블을 분해하는 것
* 제 4정규화 : 여러 컬럼들이 하나의 컬럼을 종속시키는 경우 분해하여 다중값 종속을 제거
* 제 5정규화 : 조인에 의해서 종속성이 발생되는 경우 분해
* 반정규화 == 역정규화의 개념 : 데이터베이스의 성능 향상을 위해 데이터 중복을 허용하고 조인을 중리는 데이터베이스 성능 향상 방법, 시스템의 성능 향상, 개발 및 운영의 단순화를 위해 정규화된 데이터 모델을 중복, 통합, 분리하는 데이터 모델링 기법
> 조회 속도를 향상시키지만, 데이터 모델의 유연성을 낮아
>> 비정규화는 정규화를 수행하지 않음을 읨
* 반정규화 수행 케이스
> 정규화에 충실하여 종속성 ,활용성을 향상되지만 수행 속도가 느려지는 경우
> 다량의 범위를 자주 처리해야 하는 경우
> 특정 범위의 데이터만 자주 처리하는 경우
> 요약/집계 정보가 자주 요구되는 경우
* 관계(Relationship)의 개념 : 엔터티의 인스턴스 사이의 논리적인 연관성
> 관계를 맺는다 == 부모의 식별자를 자식에 상속하고, 상속된 속성을 매핑키(조인키)로 활용 -> 부모와 자식을 연결함
* 관계의 분류
> 존재에 의한 관계, 행위에 의한 관계
> 존재 관계 : 엔터티 간의 상태
> 행위 관계 : 엔터티 간의 어떤 행위가 있는 것
* 조인 : 결국 데이터의 중복을 피하기 위해 정규화에 의해 분리, 분리되면서 두 테이블은 서로 관계를 맺게 되고, 다시 이 두 테이블의 데이터를 동시에 출력하거나 관계가 있는 테이블을 참조하기 위해서는 데이터를 연결
* 계층형 데이터 모델 : 자기 자신끼리 관계가 발생
* 상호배타적 관계 : 두 테이블 중 하나만 가능한 관계
* 트랜잭션 : 하나의 연속적인 업무 단위
> 트랜잭션에 의한 관계는 필수적인 관계 형태를 가짐
* 필수적, 선택적 관계와 ERD
> 두 엔터티의 관계가 서로 필수적일 때 하나의 트랜잭션을 형성
> 두 엔터티가 서로 독립적 수행이 가능하다면 선택적 관계로 표현
IE표기법 vs 바커표시법
원 사용 실선과 점선으로 구분
필수적관계 : 원X 실선
선택적관계 : 원O 점선

* NULL : 정해재재 않은 값, 0과 ""과는 다른 개념, 모델 설계시 각 컬럼 별로 NULL을 허용할 지를 결정
* NULL의 특성
> NULL을 포함한 연산 결과는 항상 null
> 집계함수는 null을 제외한 연산 결과 리턴

* NULL 표기법 : 바커표기법에만 존재하고 O로 되어있는 경우 NULL 허용

* 식별자 구분(대체 여부에 따른)
> 본질식별자, 인조식별자
> 본질식별자 : 업무에 의해 만들어지는 식별자
> 인조식별자 : 인위적으로 만들어지는 식별자
> 인조식별자의 단점 : 중복 데이터 발생 가능성(데이터 품질 저하), 불필요한 인덱스 생성(저장공간 낭비 및 DML 성능 저하)
> 인덱스는 원래 조회 성능을 향상시키기 위한 객체이며, 인덱스는 DML(insert/update/delete)시 index split 현상으로 인해 성능이 저하됨
------------------------------------------------------------------------------------------------------------------------------
* 관계형 데이터베이스
> 데이터베이스와 DBMS
> 데이터베이스 : 데이터의 집합
> DBMS : 데이터를 효과적으로 관리하기 위한 시스템 (ORACLE, MYSQL 등)
* 관계형 데이터베이스 구성 요소 > 계정, 테이블, 스키마
> 테이블 : DBMS의 DB안에서 데이터가 저장되는 방식
> 스키마 : 테이블이 어떠한 구성으로 되어있는지, 어떠한 정보를 가지고 있는지에 대한 기본적인 구조
* 테이블 : 액셀에서의 워크시트처럼 행과 열을 갖는 2차원 구조로 구성, 데이터를 입력하여 저장하는 최소단위, 컬럼은 속성이라고도 부름
> 특징 : 하나의 테이블은 반드시 하나의 유저(계정) 소유여야 함, 테이블 간 관계는 일대일, 일대다, 다대다 관계를 가질 수 있음, 테이블명은 중복될 수 없지만, 소유가 다른 경우 같은 이름으로 생성 가능, 테이블은 행 단위로 데이터가 입력, 삭제되며 수정은 값의 단위로 가능
* SQL : Structured Query Language, 관계형 데이터베이스에서 데이터 조회 및 조작, DBMS 시스템 관리 기능을 명령하는 언어
> 데이터 정의(DDL), 데이터 조작(DML), 데이터 제어 언어(DCL) 등~
> 대소문자 구분 X
* 관계형 데이터베이스 특징
> 데이터의 분류, 정렬, 탐색 속도가 빠름
> 신뢰성이 높고, 데이터의 무결성 보장
> 기존의 작성된 스키마를 수정하기 어려움
> 데이터베이스의 부하를 분석하는 것이 어려움
* 데이터 무결성 : 데이터의 정확성과 일관성을 유지하고 데이터에 결손과 부정합이 없음을 보증하는 것
* 데이터 무결성 종류 : 개체 무결성, 참조 무결성, 도메인 무결성, NULL 무결성, 고유 무결성, 키 무결성
* ERD : 테이블 간 서로의 상관 관계를 그림으로 표현한 것, 구성요소: 엔터티, 관계, 속성
* SQL 종류
> DDL(definition) : CREATE, ALTER, DROP, TRUNCATE > 롤백이안됨 //
> DML(manipulation) : INSERT, DELETE, UPDATE, MERGE
> DCL(control) : GRANT, REVOKE
> TCL(transaction control) : COMMIT, ROLLBACK
> DQL(query) : SELECT
* SELECT : from > where > group by > having > select > order by
> as를 사용할 때, 쌍따옴표를 사용 하는 경우 : 공백 있을 때, 특수문제 있을 때(_ 제외), 별칭 그대로 전달할 때 (cf.대소를 그대로 출력)

* 함수 : input value가 있을 경우, 그에 맞는 output value를 출력해주는 객체, from절을 제외한 모든 절에서 사용 가능
> 기능 : 기본적인 쿼리문을 더욱 강력하게 해줌, 데이터의 계산을 수행, 개별 데이터의 항목을 수정, 표시할 날짜 및 숫자 형식을 지정, 열 데이터의 유형(date type)을 변환
* 함수의 종류
> 입력값의 수에 따라 단일행, 복수행 함수로 구분
> 단일행 함수 : input 과 output의 관계가 1:1
> 복수행 함수: 여러 건의 데이터를 동시에 입력 받아서 하나의 요약값을 리턴 (그룹함수 집계함수)
* 입/출력값의 타입에 따른 함수 분류
> 문자형 함수 : 문자열 결합, 추출, 삭제 등을 수행, 단일행 함수 형태, output은 대부분 문자값
** oracle -> sql server
substr -> substring
length -> len
instr -> charindex

> 숫자형 함수: 숫자를 입력하면 숫자 값을 반환, 단일행 함수 형태의 숫자함수

> 날짜형 함수 : 날짜 연산과 관련된 함수
** oracle -> sql server
sysdate -> getdate
add_months -> dateadd
months_between -> datediff

> 변환함수 : 값의 데이터 타입을 변환
문자를 숫자로, 숫자를 문자로, 날짜를 문자로 변경
** oracle -> sql server
to_nuber, to_date, to_char -> convert
단순 변환일 경우 주로 cast 사용

> 그룹함수 : 다중행 함수, 여러 값이 input값으로 들어가서 하나의 요약된 값으로 리턴, group by 와 함께 자주 사용
** oracle -> sql server
variance -> var
stddev -> stdev

> 일반함수: 기타함수 (널 치환함수등)

* where 절
> null 조회시, is null is not null 로 조회
** 주의사항
> 문자나 날짜 상수 표현시 반드시 홑따옴표 사용 (다른 절에서도 동일 적용)
> ORACLE은 문자 상수의 경우 대소문자 구분 // MSSQL은 기본적으로 문자상수의 대소문자를 구분 X

* LIKE
> 자리수 제한 없는 모든 % // 자리수 의미 _
* JOIN (조인)
> 여러 테이블의 데이터를 사용하여 동시 출력하거나 참조할 경우 사용, FROM절에 조인할 테이블 나열
* 조인의 종류
> 조건의 형태에 따라 EQUI JOIN(등가 JOIN) : JOIN 조건이 동등 조건인 경우, NON EQUI JOIN : JOIN 조건이 동등 조건이 아닌 경우
> 조인 결과에 따라 INNER JOIN, OUTER JOIN(LEFT, RIGHT, FULL OUTER JOIN), NATURAL JOIN, CROSS JOIN, SELF JOIN
> INNER JOIN : JOIN 조건에 성립하는 데이터만
> OUTER JOIN : 성립하지 않는 데이터도
> NATURAL JOIN : 조인 조건 생략 시 두 테이블에 같은 이름으로 자연 연결
> CROSS JOIN : 조인 조건 생략 시 두 테이블의 발생 가능한 모든 행을 출력하는 조인, 카타시안곱으로 출력
> SELF JOIN : 하나의 테이블을 두 번 이상 참조하여 연결하는 조인
> ON : JOIN의 조건을 넣어서 조인 (cf. join ~ on ~)
> USING : (cf. join ~ using (~)) -> using안에 있는 것이 join의 조건
* 서브쿼리 : 하나의 SQL문 안에 포함되어 있는 또 다른 SQL문을 말함 // 반드시 괄호로 묶어야 함
> SELECT, FROM, WHERE, HAVING, ORDER BY, DML(INSERT, DELETE, UPDATE)절 // GRUOP BY NO!
* 서브쿼리종류
> 동작하는 방식에 따라, UN-CORRELATED(비연관), CORRELATED(연관)
> 서브 쿼리가 메인 쿼리 컬럼을 가지고 있지 않은 형태의 서브쿼리 == UN-CORRELATED
> 서브 쿼리가 메인 쿼리 컬럼을 가지고 있는 형태의 서브쿼리 == CORRELATED
> 위치에 따라, 스칼라, 인라인뷰, WHERE 절 서브쿼리
> SELECT에 사용하는 서브쿼리 > 스칼라 서브쿼리
> FROM 절에 사용하는 서브쿼리 > 인라인뷰
> 가장 일반적인 서브쿼리 > WHERE절 서브쿼리
** WHERE 절 서브쿼리 종류 > 단일행 서브쿼리, 다중행 서브쿼리, 다중컬럼 서브쿼리, 상호연관 서브쿼리
> 단일행 : 서브쿼리 결과가 1개의 행이 리턴되는 형태 ( = <> > >= < <=)
> 다중행 : 서브쿼리 결과가 여러 행이 리턴되는 형태
> 다중컬럼 : 서브쿼리 결과가 여러 컬럼이 리턴되는 형태
> 상호연관 : 메인쿼리와 서브쿼리의 비교를 수행하는 형태
* 집합 연산자 : SELECT 문 결과를 하나의 집합으로 간주, 합집합 교집합 차집합
> 합집밥 : UNION, UNION ALL
> 차집합 : MINUS
** 집합 연산자 사용시 주의 사항
> 두 집합의 컬럼 수 일치, 두 집합의 컬럼 순서 일치, 두 집합의 각 컬럼의 데이터 타입 일치, 각 컬럼의 사이즈는 달라도 됨, 개별 SELECT문에 ORDER BY 전달 불가(GROUP BY 가능)
* 그룹함수 : 숫자함수 중 여러값을 전달하여 하나의 요약값을 출력하는 다중행 함수, 반드시 한 컬럼만 전달, NULL은 무시하고 연산
> COUNT == 행의 수
> SUM == 값의 합
> AVG == 값의 평균( NULL은 제외한 대상의 평균을 리턴하므로 전체 대상 평균 연산시 주의)
> MIN/MAX == 최소/최대
> VARIANCE / STDDEV == 분산과 표준편차 (표준편차는 분산의 루트값)
GROUP BY
> GROUPING SET(A, B) == A별 B별 그룹 연산 결과 출력, 나열 순서 중요 X, 전체 합계 출력 X

> ROLLUP(A, B) == A별 A,B별 전체 그룹 연산 결과 출력, 나열 순서가 중요, 전체 합계 출력 O

> CUBE(A,B) : A별, B별, AB별, 전체 그룹 연산 결과 출력, 나열 순서 중요 X, 전체 총계가 출력

* 윈도우 함수 : 서로 다른 행의 비교나 연산을 위해 만든 함수, GROUP BY 하지 않고 그룹 연산 가능
> PARTITION BY 절 : 출력할 총 데이터 수 변화 없이 그룹 연산 수행할 GROUP BY 컬럼
> ORDER BY 절
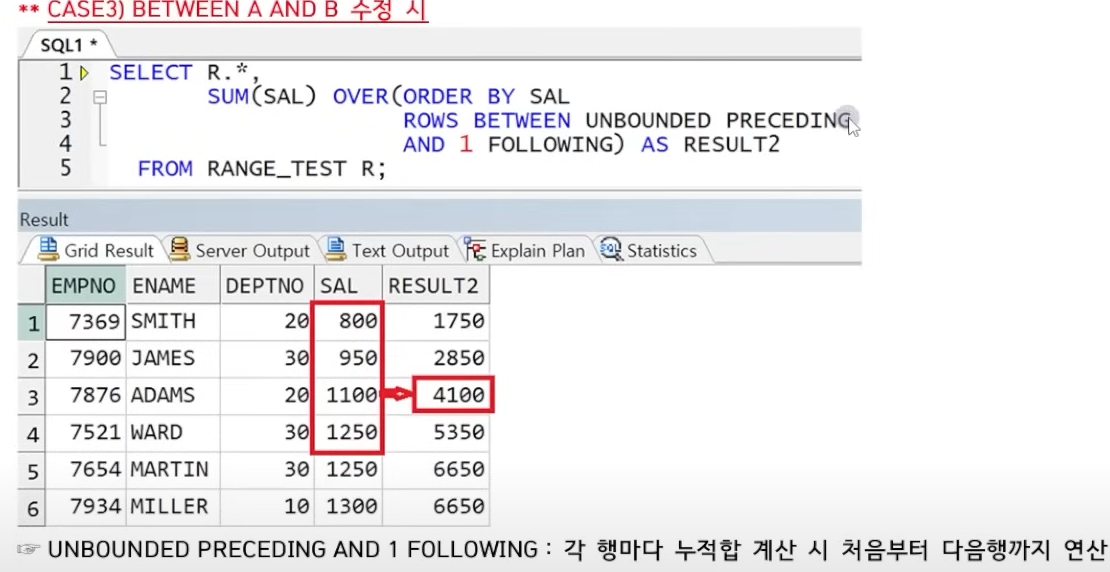
> ROWS|RANGE BETWEEN A AND B : 연산 범위 설정, ORDER BY 필수
* 그룹 함수의 형태
> SUM, COUNT, AVG, MIN, MAX
> OVER절 사용하여 윈도우 함수로 사용 가능
> 반드시 연산할 대상을 그룹함수의 입력값으로 전달
> ROWS, RANGE (값이 같더라도 각 행씩 연산, 같은 값의 경우, 하나의 RANGE로 묶어서 동시 연산 - Default)
> BETWEEN A AND B
> A: CRRENT ROW, UNBOUNDED PRECEDING, N PRECEDING (현재행부터, 처음부터- Default, N 이전부터)
> B: CURRENT ROW, UNBOUNDED FOLLOWING, N FOLLOWING(현재행까지- Default, 마지막까지, N 이후까지)

* 순위 관련 함수
> RANK(순위) : RANK WITHIN GROUP : 특정값에 대한 순위 확인, 윈도우함수가 아닌 일반함수
> RANK() OVER() : 전체 그룹 중 값의 순위 확인, ORDER BY 필수
> DENSE_RANK : 누적순위, 동일한 순위 부여 후 다음 순위가 바로 이어지는 순위 부여 방식
> ROW_NUMBER : 연속된 행 번호, 동일한 순위를 인정하지 않고 단순히 순서대로 나열한대로의 순서 값 리턴
> LAG, LEAD : 행 순서대로 각각 이전 값(LAG), 이후값(LEAD) 가져오기, ORDER BY 필수
> FIRST_VALUE, LAST_VALUE : 정렬순서대로 정해진 범위에서의 처음 값, 마지막 값 출력, 순서와 범위 정의에 따라 최솟값과 최댓값 리턴 가능, PARTITION BY, ORDER BY절 생략 가능

> NTILE : 행을 특정 컬럼 순서에 따라 정해진 수의 그룹으로 나누기 위함 함수, 그룹 번호가 리턴됨, ORDER BY 필수
* 비율관련 함수
> RATIO_TO_REPORT : 각 값의 비율 리턴, ORDER BY 불가
> CUME_DIST : 각 행의 수에 대한 누적비율, 특정 값이 전체 데이터 집합에서 차지하는 위치를 백분위수로 계산하여 출력, ORDER BY 를 사용하여 누적비율을 구하는 순서 정할 수 있음, ORDER BY 필수
> PERCENT_RANK : PERCENTILE(분위수) CNFFUR, 전체 COUNT 중 상태적 위치 출력 ( 0 ~ 1 범위내), ORDER BY 필수

* TOP N QUERY
> TOP N QUERY : 페이징 처리를 효과적으로 수행하기 위해 사용, 전체 결과에서 특정 N개 출력
> TOP-N행 추출방법: ROWNUM, RANK, FETCH, TOP N(SQL SERVER)
반응형'자격증 > SQLD' 카테고리의 다른 글
[SQLD]공부7일차_진짜문제풀이만해보기_241114 (0) 2024.11.14 [SQLD]공부6일차_2과목이론양많네...?_241113 (6) 2024.11.13 [SQLD]공부4일차_문제풀면서부족한거채워보기_241109 (2) 2024.11.09 [SQLD]공부3일차_머릿속에넣기_이론정리중_241108 (8) 2024.11.08 [SQLD]공부2일차_1과목이론공부하기+노랭이풀기_241107 (10) 2024.11.07