[정보처리기사]기사따기15일차_4과목_소프트웨어공학_3_190209
# 최초 등록일 : 2025년 1월 2일 18:42
# 최근 변경일 : 2025년 1월 2일 18:42
# 내용 : 정보처리기사 필기 4과목 공부 후 정리한 내용 올리기
이전 기사따기14일차는 아래에 링크로!!
[정보처리기사]기사따기14일차_4과목_소프트웨어공학_2_190208
# 최초 등록일 : 2024년 12월 31일 17:22# 최근 변경일 : 2024년 12월 31일 17:22# 내용 : 정보처리기사 필기 4과목 공부 후 정리한 내용 올리기 이전 기사따기13일차는 아래에 링크로!! [정보처리기사]기사
doradorabean.tistory.com
이건 많이 언급되는 단어
이건 내가 궁금한거 쳐봐서 나온 결과
------------------------------------------------------------------------------------------------------------------------------
소프트웨어 설계
설계의 기본 개념
1) 소프트웨어 설계 절차
DFD, DD분석 -> 외부 설계 -> 내부 설계(기본 설계 -> 상세 설계) -> 설계 명세서
2) 설계의 종류
- 외부 설계 : 소프트웨어의 내적인 기능보다는 외부적인 특성을 설계
- 기본 설계 : 모듈 간의 관계를 정의
- 상세 설계 : 내부 설계이며 모듈 내부의 알고리즘을 정의함
3) 설계 모형
- 문서량 기준 : 데이터 설계 < 구조 설계 < 관계 설계 < 절차 설계
- 노력 기준 : 절차 설계 < 관계 설계 < 구조 설계 < 데이터 설계
4) 구조적 설계의 기본 원칙
- 모듈화 : Modularization은 단일 기능을 갖출 수 있도록 부부적으로 묶어서 처리하는 기술
- 추상화 : Abstraction은 세부적인 설계를 배제하고 전체 흐름과 구조를 한눈에 알아볼 수 있도록 개괄적인 설계부터 세부적으로 진행
* 기능 추상화, 제어 추상화, 자료 추상화가 있다.
- 구조화 : Structured는 모듈을 수행하기 위한 위치나 시기를 전체 구조에 적절하게 배치시키는 설계 기법
- 정보 은닉 : Information Hiding은 모듈 간의 관계성을 최소화시키는 설계 기법
5) 좋은 설계의 기준
- 요구사항을 모두 표현, 객관성 있게 작성, 완전한 그림을 제공, 두 모듈 간의 상호 의존도를 약하게 해야함, 기능의 특성을 나타내야 함.
계층적 조직이 제시되어야 함, 특정한 부분가 부 기능을 수행하는 요소들로 분할되어야 함, 자료와 프로시저에 대한 분명하고 분리된
표현을 포함해야 함, 데이터와 제어 추상화를 모두 포함해야 함, 복잡도와 중복을 줄여야 함, 인터페이스를 만들어야 함.
모듈화
1) 모듈의 특징
- 코딩, 컴파일, 설계는 독립적으로 수행
- 실행은 종속적으로 수행
- 모듈은 타 모듈 호출할 수도 당할 수도 있다.
2) 모듈화의 장점 : 설계가 용이하고 복잡도를 감소, 수정이 용이하다.
3) 공유도(Fan-in)와 제어도(Fan-out) : 호출하는 모듈의 개수 및 호출 받을 수 있는 모듈의 개수를 정의하는 개념
- 공유도 : 얼마나 많은 모듈이 주어진 모듈을 호출하는가를 나타내는 척도
- 제어도 : 주어진 모듈이 호출하는 모듈의 개수
4) 모듈의 기본 요소(속성) : 입력, 출력, 기능, 기관, 내부 자료
5) 결합도에 의한 모듈의 평가 기준 : 두 모듈 간의 관계성(상호 의존성)의 척도로, 약할수록 좋은 결합이다.
- 자료 결합도 : Data Coupling은 실인수와 가인수가 독립, 단일 파일, 동종 테이블, 데이터를 넘겨주고 결과를 되돌려 받는 유형
- 구조 결합도 : Stamp Coupling은 배열이나 레코드, 자료 구조 조회, 포맷이나 구조 변화의 영향을 받는 유형
- 제어 결합도 : Control Coupling은 논리 조작을 제어하기 위한 목적, 상위 모듈에게 처리 명령을 부여하는 권리 전도 현상
- 외부 결합도 : Extern Coupling은 외부 변수에 의해 영향을 받는 두 모듈이 결합된 관계
- 공통 결합도 : Common Coupling은 실인수와 가인수가 같은 번지를 공유, 실인수 값의 영향을 항상 고려해야함.
- 내용 결합도 : Content Coupling은 모듈이 다른 모듈의 내부 기능 및 그 내부 자료를 참조하는 형태의 결합
< 결합도가 약할수록 좋은 결합이다 >

6) 응집도에 의한 모듈의 평가 기준 : 요소들이 공통적인 목적 달성을 위하여 어느 정도의 관련성이 있는가를 파악하는 척도.
- 우연적 응집도 : Coincidental Conhesion은 뚜렷한 관계 없이 묶인 모듈, 라인 등분으로 구분한 모듈
- 논리적 응집도 : Logical Cohesion은 모듈 내부의 루틴들이 같은 범주에 속하는 기능끼리 묶인 모듈
- 시기적 응집도 : Temporal Cohesion은 모듈 내부의 루틴들이 시간적으로 수행 시기가 같은 기능끼리 존재
- 절차적 응집도 : Procedural Cohesion은 모듈 내부의 루틴들이 수행 시기에 순위가 있는 기능끼리 존재
- 통신, 정보, 교환적 응집도 : Communication Cohesion은 모듈 내부의 루틴들이 작업 대상이 같은 기능끼리 존재하는 경우나 동일한
입력과 출력을 사용하느 작업들이 모인 경우
- 순차적 응집도 : Sequential Cohesion은 모듈 내부의 루틴들이 이전의 명령어로부터 나온 출력 결과를 그 다음 명령어의 입력
자료로 사용함.
- 기능, 함수적 응집도 : Functional Cohesion은 모듈 내부가 하나의 단일 기능으로 존재하는 경우, 프로그램 언어 라이브러리.
< 응집도가 강할수록 좋은 결합이다 >

구조적 설계 표기법
1) N-S Chart : Nassi-Schneiderman차트는 입출력 자료와 소프트웨어 모듈들 사이의 관계를 표현하는 뛰어난 능력을 가지고 있음.
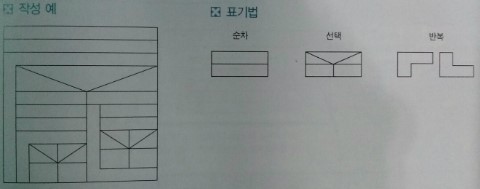
- N-S 도표 작성 시 준수 사항
* 도표는 항상 직사각형
* 제어 흐름은 맨 위에서 시작.
* 위에서 아래로 흐름
* 줄은 모두 평행 아래로 흐름
* 사각형에 빈 공간이 있을 수 있음
- N-S 도표의 특징
* 도형을 이용한 표현 방법
* 그리기가 어렵다
* 논리 구조로 표현된다
* 그래픽 설계 도구이며 상자 도표라고 한다.
* 구현이 쉽고 시각적으로 명확히 식별하는데 적합하다.
2) HIPO : Hierarchy Plus Input Process Output은 프로그램을 기능 위주로 문서화하는 하향식 설계 기법이다.
- HIPO의 종류
* 도식 목차 : 전체적인 흐름과 구조를 나타내는 도표
* 총괄 도표 : 입력, 처리, 출력 등의 기능을 명확히 표현한 도표
* 상세 도표 : 총괄 도표의 일부 기능을 구체적으로 표현한 모듈 도표
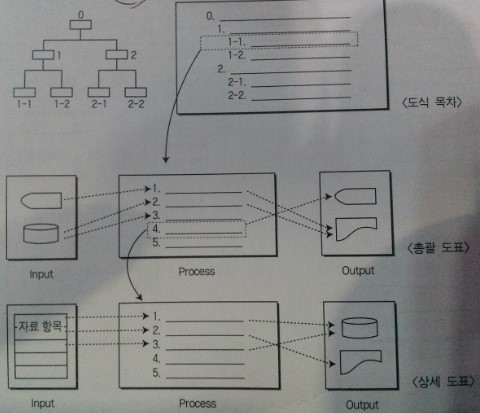
- 특징 : 분석 및 설계 도구, 입력 처리 출력으로 구성, 하향식 개발에 적당, 체계화, 기능과 자료의 관계를 동시에 표현
수정 및 유지보수 용이, 소규모 프로젝트의 적당
설계 방법론과 구현
Dijkstra의 구조적 설계(프로그래밍) 방법론
1) 기본 구조
- 순차 구조 : 알고리즘의 명세에 꼭 필요한 프로세싱 단계를 구현
- 선택 구조 : 프로세싱을 선택하는 기능
- 반복 구조 : 루틴의 반복 처리
2) 구조적 설계 방법의 특징 : 표준화, 단일 입출력으로 처리, 순차 선택 반복 구조만을 이용, 명료성을 증대, GO TO문을 사용, 검증이 용이, 유지보수가 용이, 이해가 쉬움
자료 흐름 중심 설계 방법론
1) 자료 흐름 설계 과정 : 유형을 설정, 경계를 표시, 경험적 방법으로 구체화
2) 변환 사상 : Transform Mapping은 DFD를 전체 혹은 일부를 분할해서 구조도로 변화하는 작업
자료 구조 중심 설계 방법론
1) DSSD 방법론 : Warnier-Orr 기법
출력 자료 정의 -> 논리적 레코드 정의 -> 사건 분석 -> 물리적 레코드 정의 -> 논리적 절차 정의 -> 물리적 절차 정의
2) JSD 방법론 : Jackson 기법
자료 구조 정의 -> 구조도 작성 -> 연산 목록 작성 -> 구조문 작성
소프트웨어 구현의 이해 <프로그램 언어를 이용하여 변환하는 과정>
1) 프로그램 언어의 선택 기준 : 언어의 응용 영역, 알고리즘 난이도, 대상 업무의 성격, 실행 환경, 경험과 지식, 자료구조 난이도,
개발자 과거 실적
2) 프로그램의 기본적인 제어 구조 : 순차, 선택, 반복, 되부름
3) Fairley 프로그램 언어의 데이터 유형 ------------------ X
4) 프로그래밍 코딩 방법
- 문 구성 방법 : 단순하고 직접적인 것, 복잡한 조건은 피함, 긍정적처리, 과중한 중첩은 회피, 빠른 연산자 이용, 주석을 활용
- 데이터 선언 : 누구나 이해할 수 있는 데이터명 사용, 포인터와 리스트 사용 피함, 다차원 배열 피함
- 입력과 출력 : 입출력 요청 수를 최소화, 입력시 버퍼 이용, 블록화 되어 있어야 함.
객체지향 개념
객체지향(Object Oriented)의 개념
1) 출현 배경 및 개념 : 개발에 투입되는 시간과 비용 등 여러 가지의 문제점을 해결하고 어떻게 하면 소프트웨어 개발을 손쉽게 하나?
모듈의 형태와 모듈 간의 관계의 관심을 둔다.
2) 객체지향 기술의 이해 : 객체의 기본적 요소를 자료 구조라고 하고, 기본적인 요소를 사용하는 방식 및 기능을 함수로 정의
3) 객체의 정의 : 객체 = 어트리뷰트(속성) + 메소드(프로시져)
* 객체 : Object는 필요한 자료 구조와 이에 수행되는 함수들을 가진 하나의 소프트웨어 모듈, 명사형이다.
* 어트리뷰트 : Attribute는 객체의 속성 및 상태를 표현
* 메소드 : Method는 객체의 구체적인 연산을 정의, 동사형이다.
4) 객체지향 프로그래밍의 의미 : OOP(Object Oriented Programming)이라 하며 데이터와 그 데이터를 처리할 기능을 하나의 클래스
(객체의 타입)로 정의하고 이 클래스에서 여러 개의 인스턴스(복사본)를 만들어서 이러한 복사본들의
객체들과 상호 작용(메세지 전달)에 의해서 프로그래밍 되는 것이다.
5) 객체지향 기술의 장점 : 대형 프로젝트 개발에 적당, 재사용률 높아짐, 확장성의 증대, 신속한 개발, 자연적 모델링, 사용자 타입 중심
6) 객체지향 기술의 단점 : 설계가 어려우, 실행속도가 느려짐
객체지향 기술의 용어
1) 클래스 : Class는 하나 이상의 유사한 객체들을 묶어 공통된 특성을 표현한 데이터 추상화를 의미

2) 인스턴스 : Instance는 클래스에 속하는 구체적인 객체를 의미하며 클래스로 정의된 객체의 요소로 객체의 복사본이라고 할 수 있다.
3) 어트리뷰트 : Attribute는 객체 안에 존재하는 절대적 자료형이다.
4) 메소드 : Method는 객체가 메시지를 받아 실행해야 할 객체의 구체적인 연산을 정의한 것. 함수 또는 프로시져와 같다.
5) 상속성 : 상위클래스가 갖는 속성과 연산을 그대로 물려받는 것, 재사용성이 생긴다
* 베이스 클래스 : Base class 기본적인 특성을 정의한 상위 클래스
* 파생 클래스 : Derived class 베이스 클래스로붙 자료 구조, 함수의 기능을 상속받아 자신의 것처럼 이용
6) 다중 상속 : Multiple Inheritance 하나의 객체가여러 개의 상위 클래스로부터 자료 구조와 함수를 상속받는 것
7) 다형성 : Polymorphism은 같은 상위 객체에서 상속받은 여러 개의 하위 객체들이 다른 형태의 특성을 갖는 객체
* 다형성의 특징 : 객체에 따라 다른 방법으로 응답할 수 있도록 설계, 일반화된 객체를 이용하여 특정 객체가 가진 특성 이용 가능
객체를 정의할 때 자료 구조와 함수가 상황에 따라 적절한 것으로 선택되어 이용, 오버로딩
8) 캡슐화 : Encapsulation은 객체를 정의할 때 연관된 잘 구조와 함수를 한 테두리로 묶는 것을 말함
* 캡슐화이 특징 : 프로그램의 컴포넌트로 재사용, 재사용이 용이, 외부와 경계를 만들고 필요한 인터페이스만을 밖으로 드러냄
* 캡슐화의 장점 : 재사용, 단순화, 오류가적음
9) 정보 은폐 : Information Hiding은 자료 구조나 함수의 기능을 외부의 영향을 받거나 주지 않도록 설계
* 정보 은폐의 특징 : 자료 구조만 은폐하고 메소드는 제한적으로 접근을 허용함.
* 추상성 : Abstraction은 하위 객체의 공통된 특성을 묘사하기 위한 객체
* 메시지 : Message는 객체와 객체 사이에 인터페이스 형식
객체지향 개발 방법
객체지향 개발 순서
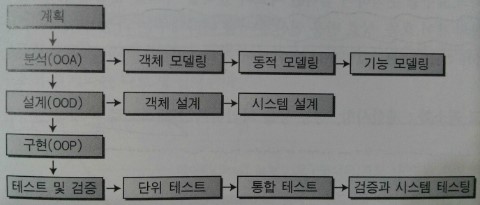
객체지향 분석(OOA : Object Oriented Analysis)
1) 객체지향 분석의 특징 : 형식적인 전략을 기술하는 단계, 클래스를 식별, 문제를 모형화
2) 객체지향 분석의 순서 (OMT : Object Modeling Technique, 람바우 방법) : 객체 모델링 -> 동적 모델링 -> 기능 모델링
* 객체 모델링 : Object Modeling은 문제 영역에서 요구되는 객체를 찾아내고 객체의 속성, 연산을 식별하는 단계
* 동적 모델링 : Dynamic Modeling은 전 단계에서 생성된 객체 모형들의 행위, 상태, 조건을 파악하는 단계
* 기능 모델링 : Functional Modeling은 사용자 요구를 분석 후 입 출력 자료를 결정, 객체의 제어 흐름, 상호 반응 연산 순서를
나타내주는 과정
객체지향 설계(OOD : Object Oriented Design)
1) 객체지향 설계의 특징 : 프로그램으로 실행될 수 있는 문제 영역의 분석 모형을 구체적인 절차로 표현하는 것,
대화식 프로그램의 개발에 적합, 클래스를 객체, 속성을 자료 구조로, 연산을 알고리즘으로 표현
2) 객체지향 설계의 순서 : 문제의 정의 -> 요구 명세화 -> 객체 연산자 정의 -> 객체 인터페이스 결정 -> 객체의 구현
* 객체 설계(객체 연산자 정의) : 객체 연산자를 정의하여 객체를 설계
- 객체 모델 : 구성하고 있는 클래스와 속성을 객체와 자료 구조로 표현
- 동적 모델 : 자료와 자료에 가해지는 프로세스를 묶어 정의하고 관계를 규명
- 기능 모델 : 서브 클래스와 메시지 특성을 세분화 하여 세부 사항을 정제화
* 시스템 설계 : 객체 인터페이스를 결정하는 행위로 정의된 객체 간의 인터페이스를 정하여 전체적 시스템을 설계한다.
객체 모형을 특성별로 구분한 서브시스템으로 분할 (계층 차트를 그림)
3) 구조적 설계와 객체지향 설계의 계층
* 객체지향 설계
- Responsibilitiies Layer : 속성과 연산들에 대한 메타 데이터와 알고리즘을 표현
- Message Layer : 객체와 객체 간의 인터페이스를 표현
- Class & Object Layer : 전체 객체를 구체적으로 표현
- Subsystem Layer : 요구사항을 지원하는 기술적인 기반 구조를 구현
객체지향 프로그래밍(OOP : Object Oriented Programming)
- 클래스를 정의, 클래스와 클래스의 계층을 정의, 객체생성, 상속과 다형성을 활용, 메시지간 객체간 상호작용
객체지향 테스트
1) 단위 테스트 : 가장 작은 단위로 캡슐화된 클래스나 객체를 검사
2) 통합 테스트 : 객체의 결합 검사
* 쓰레드-기반 테스트 : Thread-Based Testing은 입력이나 이벤트에 응답하는데 요구되는 클래스들의 집합을 통합
* 사용-기반 테스트 : Use-Based Testing은 클래스들을 독립적으로 검사한 후 상위 클래스와 결합
* 검증과 시스템 테스트 : 성능이나 인터페이스상 오류는 없는지 검사
* 하향식 통합 검사 방법 : 모듈을 상위 메뉴에서부터 아래로 결합하면서 검사 <-> 상향식 통합 검사 방법
객체지향 분석 방법론의 종류
1) Rambaugh Method : 객체지향 분석을 3개의 모형인 객체 모형, 동적 모형, 기능 모형으로 분리하여 접근
2) E-R Diagram : 데이터 구조들과 그들 간의 관계들을 표현하고 객체 모형을 만드는 방법론
3) Booch Method : 미시적 개발 프로세스, 거시적 개발 프로세스로 접근하는 방법 (다이어그램, 클래스 계층 정의, 클러스터링 등)
4) Coad와 Yourdon Method : 객체의 행위를 모델링
5) Jacobson Method : 사용자가 제품 또는 시스템과 어떻게 상호 작용하는지를 서술한 시나리오로 접근
6) Wirfs-Brocks Method : 고객 명세의 평가로 시작하여 설계로 끝나는 연속적인 프로세스로 접근하는 방법
소프트웨어 검사
소프트웨어 검사의 정의
1) 소프트웨어 검사의 이해 : 작성된 소프트웨어를 대상으로 오류를 찾아내는 작업, 오류는 반드시 존재하며 검사를 통해서 100% 검출
한다는 것은 불가능한 일.
2) 검사 관련 용어 정의
* 검사 : Testing은 오류를 찾는 작업
* 디버깅 : Debugging은 검사로 찾아낸 오류를 수정
* 검증 : Verification은 개발된 소프트웨어와 사용자의 요구분석 명세서와의 차이를 확인
* 검토 회의 : Walk-through는 소프트웨어 생명주기의 각 단계마다 산출된 명세서를 가지고 다음 단계로 넘어가기 전에 오류를
찾아내는 작업
* 정형 기술 검토 : FTR은 소프트웨어에 관련된 여러 사람이 모여 회의함
검사방법
1) 검사 방법의 이해 : 오류를 찾기가 좋은 검사 경우를 선택하는 것. 화이트 박스 검사와 블랙 박스 검사가 있음.
2) 화이트 박스 검사 : White Box 검사는 모듈 안의 작동을 직접 관찰. 논리적 구조를 체계적으로 점검. 원시 코드의 논리적인 구조를 커버
충분히 실행되는가를 보장하기 위한 검사, 논리적인 경로를 검사
* 종류 : 기초 경로 검사, 루프 검사, 데이터 흐름 검사, 조건 검사
* 찾을 수 있는 오류 : 자세하고 세부적 오류를 찾을 수 있음
3) 블랙 박스 검사 : Black Box 검사는 제품의 각 기능이 완전히 작동되는 것을 입증하는 검사, 입출력의 정확성을 판단함.
* 종류 : 균등 분할, 한계값 분석, 원인-결과 그래프, 오류 예측, 비교 검사
* 찾을 수 있는 오류 : 비정상적인 자료를 입력해도 오류 처리를 수행하지 않는 경우의 오류를 찾을 수 있음
인터페이스 오류, 자료 구조상의 오류, 성능 오류, 경계 값 오류
화이트 박스 검사(White Box Testing) 방법
1) 기초 경로 검사 : Basic Path Testing은 프로그램 전체의 내부 구조나 모듈 내부의 구조를 대상으로 검사하는 방법, 대상의
모든 논리적인 경로를 복잡도로 계산하여 구한 후 경로를 수행할 수 있는 검사 경우를 직접 입력하여 오류를 찾는 방법.
* 기초 경로 검사 순서 : 흐름 도표를 작성 -> 복잡도 구함 -> 검사 경우를 결정 -> 판단
- 복잡도 계산 : Cyclomatic Complexity 계산은 흐름 도표의 영역의 수이며 검사하고자 하는 루틴이 수행되는 모든 경로를 의미함
복잡도는 6 ~ 10이 가장 적당하며 판단은 다음 2가지 방법으로 한다.
* 오일러(Euler) 공식 이용 : V - E + R = 2
V : 노드의 수 E : 간선의 수 R : 면의 수(복잡도)
즉. E - V + 2 를 한 값이 복잡도가 된다!
* 인접 행렬 이용 : 그래프를 보고 화살표가 한 번에 갈 수 있으면 '1'이고, 갈 수 없으면 '0'으로 정함

* 복잡도의 판정 : <5 이하 - 단순> <6 ~ 10 - 구조적이고 안정> <20 이상 - 매우 복잡> <50 이상 - 비구조적이고 불안정>
2) 루프 검사 : Loop Testing은 반복문에서 오류를 찾는 검사 경우를 결정하는 방법
블랙 박스 검사(Black Box Testing) 방법
1) 균등 분할 : Equivalence Partitioning은 입력 명세 조건에 따라 설정, 입력 조건에 대하여 타당한 값과 그렇지 못한 값을 설정
* 오류 처리 메시지 : 이해하기 쉬워야 함, 구체적 설명이 제공, 부정적인 내용은 적극적으로 알리도록 함, 쉬운 의미 전달
2) 한계값 분석 : Boundary Value Analysis는 범위의 한계 부분을 집중적으로 검사하는 경우를 정하여 검사하는 방법
3) 원인 - 결과 그래프 : Cause - Effect Graphing은 여러 개의 입력 자료와 출력 결과가 있는 경우에 사용되는 방법
4) 오류 예측 : Error Guessing은 경험적으로 있을 법한 오류 데이터를 입력하여 검사하는 방법
소프트웨어 검사 전략
소프트웨어 검사 순서
1) 소프트웨어 검사 순서의 이해 : 사용자의 요구 명세서에 있는 내용으로 구현되어었는지, 성능이나 시스템에 문제가 없는지 검사
2) 소프트웨어 검사 순서 : 검사 순서는 소프트웨어 개발 순서와 반대로 진행하게 된다.

단위 검사(코드 검사, 모듈 검사, 프로그램 설계 검사)
- 모듈을 대상으로 화이트 박스 검사를 실시하는 방법으로 인터페이스 검사, 자료 구조 검사, 경로 검사, 오류 처리 검사, 한계 값 검사
통합 검사(Integraion 결합 검사, 구조 설계 검사)
- 단위별(모듈별)로 결합하면서 오류를 찾는 방법
1) 하향식 통합 검사 : Top Down방식은 상위 모듈에서 하위 모듈로 결합하면서 오류를 찾는 방법
* 하향식 통합 검사 순서 : 전체 프로그램을 매번 실행하고 종속적인 모듈은 가짜 모듈(Stub)로 대치 -> 가짜 모듈을 실제 모듈로 대치
-> 각 모듈이 통합되면 검사를 실시 -> 통합될 때마다 회귀 검사를 실시
* 회귀 검사 : Regression Testing은 변경이 부작용을 전파하지 않았다는 사실을 확인하기 위해 이미 수행헀던 검사 부분을
다시 검사해 보는 것
2) 상향식 통합 검사 : Bottom Up방식은 클러스터1를 실행할 수 있는 시험 가동기2가 필요. 중요한 모듈을 먼저 검사할 수 있는 장점.
* 상향식 통합 검사 순서 : 낮은 수준의 모듈들을 클러스터로 결합 -> 시험 가동기 작성 -> 클러스터를 검사 ->
시험 가동기를 제거하고 클러스터를 상위로 결합 -> 전체적인 소프트웨어 구조로 완성
3) 혼합식 통합 검사 : Mixed 통합 검사는 위 두가지의 장점을 결합한 방식으로 샌드위치(Sandwich)식 통합 방식이라고도 함.
검증 검사(Validation Test)
- 내적, 외적인 요구를 실제 구현된 프로그램과 비교하면서 검사하는 것을 검증이라 함
1) 외부 검사 : 외부 명세대로 수행되는가를 비교하면서 검사
2) 내부 검사 : 내부 명세대로 수행되는가를 비교하면서 검사
3) 알파 검사 : Alpha Test는 사용자를 제한된 환경으로 초대하여 프로그램을 수행하게 하고 개발자는 사용자가 프로그램을 어떻게
수행하는가를 지켜보며 오류를 찾는 검사
4) 베타 검사 : Beta Test는 다수의 사용자를 제한되지 않은 환경에서 프로그램을 사용하게 하고 오류가 발견이 되면 개발자에게
통보하는 방식의 검사 방법
시스템 검사
- 전체 시스템의 기능이나 성능에는 문제가 없는지를 확인하는 검사
1) 확인 검사 : 개발된 소프트웨어에 이해 관계가 있는 모든 사람이 참석하여 오류를 찾는 방법
2) 보안 검사 : 비밀 번호가 어느 정도의 보안 능력을 갖고 있는지 추리하는 검사
3) 무결성 검사 : 사용 후에도 항상 정확성과 유효성을 유지하는 검사
4) 스트레스 검사 : 소프트웨어에 다양한 형태의 스트레스를 주어 검사하는 방법. 즉, 버닝테스트
5) 부피 검사 : 소프트웨어가 처리할 수 있는 한계치를 입력하여 검사하는 방법
6) 메모리 검사 : 주기억 장치나 보조 기억 장치의 활용도를 검사
7) 성능 검사 : 솦트웨어의 실시간 성능을 검사
8) 호환성 검사 : 기존에 사용하던 파일 및 소프트웨어와의 호환성을 검사
9) 신뢰성 검사 : 복잡한 계산이나 오류에 대처할 수 있는 능력을 검사
10) 회복 검사 : 회복이 적절하게 수행되는지를 검사
11) 사용 용이성 검사 : 인간 공학적 측면에서 검사. UI, UX 검사
12) 유지보수 용이성 검사 : 새로운 환경으로 적응을 위한 유지보수, 오류가 최소화될 수 있는지 검사
정형 기술 검토(FTR : Formal Technical Reviews, 정형화된 검토 회의)
1) 정형 기술 검토의 목적 : 요구사항과 일치되는 정도, 표준화되었는지, 정형화된 소프트웨어가 개발되도록, 프로젝트를 관리
2) 정형 기술 검토의 제약사항 : 3~5명 참가, 사전 준비 필요, 각 개인에게 2시간 이상 요구 안됨, 검토 모임 시간은 2시간 이내로.
3) 정형 기술 검토의 검토 지침
* 제품 검토의 집중성 : 수정이아닌 검토에 집중
* 사전 준비성 : 검토를 위한 자료를 사전에 배포하여 검토하도록 함.
* 의제의 제한성 : 의견을 제한하되 충분히 받아드림
* 안건 고수성 : 안건을 세우며 고수한다.
* 논쟁 반박의 제한성 : 논쟁과 반박을 제한
* 문제 공개성 : 문제 영역을 공개
* 참가 인원의 제한성 : 참가자 수 제한함
* 문서성 : 발견된 오류는 문서화
오류 증폭 모형
1) 오류 증폭 모형의 이해 : 생명주기의 매 단계마다 확인 검사를 통하여 검사하면 많은 양의 오류를 찾게 되고 수정될 것.